SELECT / ALIAS
SELECT 문은 SQL에서 가장 기본이 되는 문장 중 하나로, 데이터베이스에서 원하는 정보를 가져오는 데 사용된다.
SELECT의 기능은 다음과 같다.
- 특정 열 선택: SELECT 문을 사용하여 원하는 열(칼럼)만 선택할 수 있다. 이를 통해 필요한 정보만 가져올 수 있다.
- 모든 열 선택: 별표(*)를 사용하여 모든 열을 선택할 수 있다. 이를 통해 테이블의 전체 데이터를 가져올 수 있다.
- 조건에 맞는 행 선택: WHERE 절을 사용하여 원하는 조건에 맞는 데이터만 선택할 수 있다. 이를 통해 특정 조건에 따라 검색 결과를 필터링할 수 있다.
- 정렬: ORDER BY 절을 사용하여 선택한 열을 기준으로 결과를 정렬할 수 있다. 오름차순(ASC) 혹은 내림차순(DESC)으로 정렬할 수 있습니다.
- 중복 제거: SELECT DISTINCT 문을 사용하여 중복된 값을 제거할 수 있다.
- 연산 및 함수: SELECT 문에서는 다양한 연산과 함수를 사용할 수 있다. 예를 들어, 숫자 열의 합계(sum), 평균(avg), 최대값(max), 최소값(min) 등을 계산할 수 있다.
해당 데이터에 대해 작업을 수행한다.
create table melon_chart (
ranking int,
song varchar(50),
singer varchar(20),
album varchar(50),
like_no int
);
insert into melon_chart values (1, 'Super Shy', 'NewJeans', 'NewJeans 2nd EP Get Up', 115766);
insert into melon_chart values (2, 'Seven (feat. Latto) - Clean Ver.', '정국', 'Seven (feat. Latto) - Clean Ver.', 124699);
insert into melon_chart values (3, 'ETA', 'NewJeans', 'NewJeans 2nd EP Get Up', 60239);
insert into melon_chart values (4, '퀸카 (Queencard)', '(여자)아이들', 'I feel', 125309);
insert into melon_chart values (5, 'I AM', 'IVE (아이브)', 'Ive IVE', 188847);
insert into melon_chart values (6, '헤어지자 말해요', '박재정', '1집 Alone', 96577);
insert into melon_chart values (7, '이브, 프시케 그리고 푸른 수염의 아내', 'Le SSERAFIM (르세라핌)', 'UNFORGIVEN', 96863);
insert into melon_chart values (8, 'Spicy', 'aespa', 'MY WORLD - The 3rd Mini Album', 115388);
insert into melon_chart values (9, 'Steal The Show (From 엘리멘탈)', 'Lauv', 'Steal The Show (From 엘리멘탈)', 108665);
insert into melon_chart values (10, 'New Jeans', 'NewJeans', 'NewJeans 2nd EP Get Up', 57308);
중복된 값이 있을때, DISTINCT로 중복이 제거된 값을 확인할 수 있다.

SELECT * FROM melon_chart;
SELECT DISTINCT singer FROM melon_chart ;
SELECT count(DISTINCT singer) FROM melon_chart
*은 데이터를 전부 가져오라는 것을 의미한다. 저 상태는 깡통차와 같다. 아무런 옵션이 없기 때문이다.
DISTINCT를 통해서 중복이 제거된 고유값들만 볼 수가 있다. 또한 count 옵션을 걸어 중복을 고려한 총 데이터의 집계를 확인 할 수 있다.
이때, 아래와 같이 AS로 header의 출력에 옵션을 걸어 Header명을 간결하게 출력되도록 할 수 있다.
만약에 한글이나 특수기호를 Header명에 포함할 경우 따옴표로 정의한다.

SELECT count(DISTINCT singer) as '가수(명)' FROM melon_chart ;
- 다양한 경우들
singer가 NewJeans일때 ranking과 song 컬럼을 불러온다
SELECT ranking, song from melon_chart where singer = 'NewJeans';
singer가 NewJeans이고 ranking이 6위 미만인 값을 다 불러온다.
SELECT * from melon_chart where singer = "NewJeans" and ranking < 6;
singer가 정국이거나 박재정일 경우의 값을 모두 불러온다.
SELECT * FROM melon_chart where singer = '정국' or singer = '박재정';
데이터양이 방대할 경우, LIMIT으로 조회하고자 하는 데이터의 숫자를 제한해줄 수 있다. 이때는 LIMIT 뒤에 숫자에 따라 출력양이 정해지게 된다. 조회되는 순서는 DB가 저장된 순서이다. python의 head와 같은 용도로 사용한다.
SELECT * FROM melon_chart LIMIT 3;
WHERE(+ IN, LIKE, BETWEEN)
WHERE절을 통해 특정 조건에 부합하는 데이터들만 조회할 수 있다.
- IN
어떠한 컬럼에 특정값이 포함된 경우를 조회하고 싶을때 사용한다.
‘이 안에 있다면 보여주세요!’라고 생각할 수 있다. 반대로 NOT IT일 경우 ‘이 안에 있다면 제외해 주세요!’로 생각할 수 있다.
SELECT * FROM melon_chart WHERE song in ('I AM', 'Super Shy', 'Spicy');
SELECT * FROM melon_chart WHERE song = 'I AM' or song = 'Super Shy' or song = 'Spicy';

song의 값이 i am 또는 super shy 또는 spicy 일 경우 출력한다. 두 쿼리는 같은 의미이다.
만약 or 과 and을 혼용하고 싶을 경우 아래와 같이 확실하게 괄호를 넣어 사용하도록 하자.
아래 쿼리에 괄호가 없을 경우 마지막 부분의 ‘song = 'Spicy' and singer = 'NewJeans'에 괄호가 되어 있는거로 인식한다.
SELECT * FROM melon_chart WHERE (song = 'I AM' or song = 'Super Shy' or song = 'Spicy') and singer = 'NewJeans';
- LIKE
부분적으로 일치하는 칼럼을 찾을때 사용한다.
_ : 글자숫자를 정해줌(EX 컬럼명 LIKE '홍_동')
% : 글자숫자를 정해주지않음(EX 컬럼명 LIKE '홍%')
SELECT * FROM melon_chart WHERE song like '이브%'; #이브로 시작하는 노래
SELECT * FROM melon_chart WHERE song like '%말해요';
SELECT * FROM melon_chart WHERE song like '%S%'; #S가 들어간 모든 조건
SELECT * FROM melon_chart WHERE singer like '정_'; #%가 어떤 문자열을 의미한다면 _는 문자 하나
SELECT * FROM melon_chart WHERE song like '_카%';
만약 %나 _를 포함하는 값을 조회하고 싶다면? ESCAPE문을 활용하자!
찾고싶은 기호 앞에 ESCAPE 문자를 정의하여 사용한다. ESCAPE문자에는 \, #등 모든 문자가 가능하지만, 실제로 검색시에 잘 쓰지 않는 문자를 사용하는것이 좋다.
SELECT * FROM test WHERE col like '%#%%' ESCAPE '#'; # %기호가 포함된 데이터 출력
SELECT * FROM test WHERE col like '%$%%' ESCAPE '$'; #동일하게 작용
- BETWEEN
말 그대로 특정 값 사이에 있는 데이터를 조회한다. 여기서 주의할 점은 경계값을 포함한다는 것. 즉 이상과 이하로 조회된다.
SELECT * FROM melon_chart WHERE like_no BETWEEN 100000 AND 150000;
ORDER BY(+ LIMIT)
SELECT 문을 사용할 때 출력되는 결과물은 테이블에 입력된 순서대로 출력되는 것이 기본이다. 하지만 우리는 가끔은 내림차순으로 혹은 오름차순으로 정렬된 데이터들이 필요할 때가 있다. 이때 사용하는 것이 ORDER BY 절.
기본값은 ASC(오름차순)이다.
SELECT * FROM melon_chart ORDER BY ranking;
SELECT * FROM melon_chart ORDER BY ranking desc; #내림차순
SELECT song,singer FROM melon_chart ORDER BY ranking desc; #정렬된 두 컬럼 출력
SELECT * FROM melon_chart WHERE singer not in ('정국','박재정') ORDER BY song; #정국과 박재정이 아닌 값들에 대해 정렬
다음과 같이 ORDER BY 절에 두 컬럼이 적용됐다면, 첫번째 컬럼에 우선 정렬되고 중복된 값들에 대해서만 다시 정렬한다.
SELECT * FROM melon_chart ORDER BY singer, like_no desc;
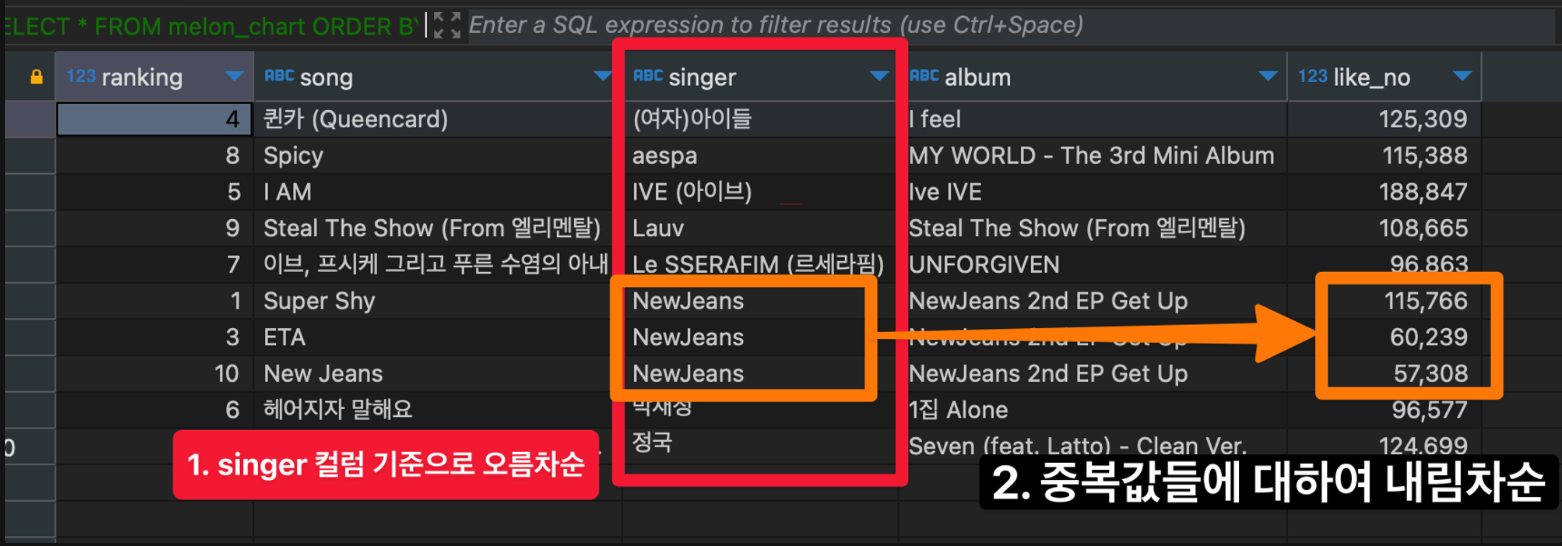
- LIMIT 정렬후 Return할 데이터 수를 정한다. 만약 두번째 쿼리문과 같이 되어있다면 4번째 데이터 부터 5개의 row를 return하라는 것을 의미한다. 페이징할때 많이 쓴다고 한다.
SELECT * FROM melon_chart ORDER BY like_no desc limit 3;
SELECT * FROM melon_chart ORDER BY like_no desc limit 3,5; #4번째 데이터 부터 5개 row를 불러와라. 페이징할때 많이 씀
Aggregate Function
집계 함수는 여러 행으로부터 하나의 결괏값을 반환하는 함수이다. SELECT 구문에서만 사용되며, 컬럼끼리의 연산을 수행한다.
COUNT, SUM, MIN, MAX, AVG 등이 쓰이며 Python이나 엑셀 등과 같이 기능한다.
SELECT COUNT(*) from melon_chart; #데이터의 건수 return/ *대신 숫자여도 똑같이 기능
#컬럼명이 들어갔을땐 null값 제외 건수 return
SELECT SUM(like_no), SUM(ranking) FROM melon_chart; #각각 총합 return
SELECT AVG(like_no) FROM melon_chart; #null 값은 아예 없는 데이터로 취급. 0이 아님.
좋아요 수가 100000개 초과인 컬럼이 몇개 있는지를 물어보는 쿼리문이다.
#응용
SELECT COUNT(*) from melon_chart WHERE like_no > 100000;
GROUP BY
특정 칼럼을 기준으로 집계 함수를 사용하여 건수(COUNT), 합계(SUM), 평균(AVG) 등 집계 데이터를 추출할 때 사용한다. GROUP BY 절에서 기준 칼럼을 여러 개 지정할 수 있으며, HAVING 절을 함께 사용하면 집계 함수를 사용하여 WHERE 절의 조건절처럼 조건을 부여할 수 있다. GROUP BY 절은 중복제거를 할 때도 사용 가능하다. 편하게 보기 위해 ORDER BY를 사용하여 쿼리문을 작성하는 것이 좋다.
아래의 테이블을 사용한다.
create table animal_info (
animal varchar(20),
type varchar(20),
name varchar(30),
age int
);
insert into animal_info values ('강아지', '포매라이언', '망고', 3);
insert into animal_info values ('고양이', '먼치킨', '두부', 5);
insert into animal_info values ('고양이', '샴', '망고', 5);
insert into animal_info values ('고양이', '페르시안', '제니', 1);
insert into animal_info values ('강아지', '치와와', '칫치', 11);
insert into animal_info values ('강아지', '푸들', '꼼데', 7);
insert into animal_info values ('강아지', '포매라이언', '몽이', 1);
insert into animal_info values ('강아지', '치와와', '초코', 5);
insert into animal_info values ('고양이', '먼치킨', '살구', 9);
insert into animal_info values ('고양이', '페르시안', '캔디', 13);
insert into animal_info values ('강아지', '푸들', '가르송', 6);
insert into animal_info values ('강아지', '진돗개', '백구', 10);
insert into animal_info values ('강아지', '웰시코기', '까미', 12);
insert into animal_info values ('고양이', '러시안 블루', '구름', 1);
insert into animal_info values ('고양이', '먼치킨', '까미', 4);
insert into animal_info values ('고양이', '샴', '도리', 8);
insert into animal_info values ('고양이', '러시안 블루', '라떼', 4);
insert into animal_info values ('고양이', '먼치킨', '녹두', 2);
insert into animal_info values ('강아지', '포매라이언', '별이', 8);
insert into animal_info values ('고양이', '페르시안', '나나', 5);
다음과 같이 사용할 경우 에러가 난다**. G**ROUP BY 절에서는 집계 함수를 제외한 다른 열을 선택할 수 없기 때문이다. 따라서 두번째 쿼리문처럼 기준 컬럼까지 넣어서 사용해준다.
SELECT * FROM animal_info GROUP BY animal; #에러남.
SELECT animal FROM animal_info GROUP BY animal; #
SELECT animal, max(age) FROM animal_info GROUP BY animal; #group별 누가 나이가 가장 많은지
#group별 누가 나이가 가장 많은지 + name까지 알고 싶다고 아래처럼 하면 error => GROUP BY 절에서는 집계 함수를 제외한 다른 열을 선택할 수 없기 때문
SELECT animal, max(age),name FROM animal_info GROUP BY animal;
#age별 분포 확인
SELECT age, COUNT(*) FROM animal_info GROUP BY age ORDER BY age;
#동물별, 종별 분류
SELECT animal, type, COUNT(*) FROM animal_info GROUP BY animal, type ORDER BY animal;
#강아지만 보고 싶다면?
SELECT animal, type, COUNT(*) FROM animal_info WHERE animal ='강아지' GROUP BY animal, type;
SELECT animal, type, MIN(age), MAX(age) FROM animal_info GROUP BY animal, type ORDER BY animal;
월별 매출, 회원 연령대별 가입현황 관련해서 많이 쓰이니 숙지하는게 신상에 좋을 것이다.
Having
HAVING 절은 그룹화한 결과에 조건을 걸고자 할 때 사용한다. HAVING 절은 집계함수를 이용한 조건비교를 할 때 사용한다. WHERE 절에서는 집계함수를 이용할 수 없다는 점이 차이점이다
WHERE은 집계함수를 이용할 수 없기 때문에 아래 쿼리에선 에러가 발생한다.
SELECT animal, type, count(*) FROM animal_info WHERE COUNT(*) > 2 GROUP BY animal, type; #오류
다음과 같이 WHERE절이 아닌 HAVING을 이용해서 집계함수를 사용하여 조건을 걸어 줄 수 있다.
SELECT animal, type, count(*) FROM animal_info GROUP BY animal, type HAVING COUNT(*) > 2;
정렬을 시킬경우 쿼리 맨 마지막에 ORDER BY절을 추가해주면 된다.

SELECT animal, type, count(*) FROM animal_info GROUP BY animal, type HAVING COUNT(*) > 2 ORDER BY COUNT(*) DESC ;
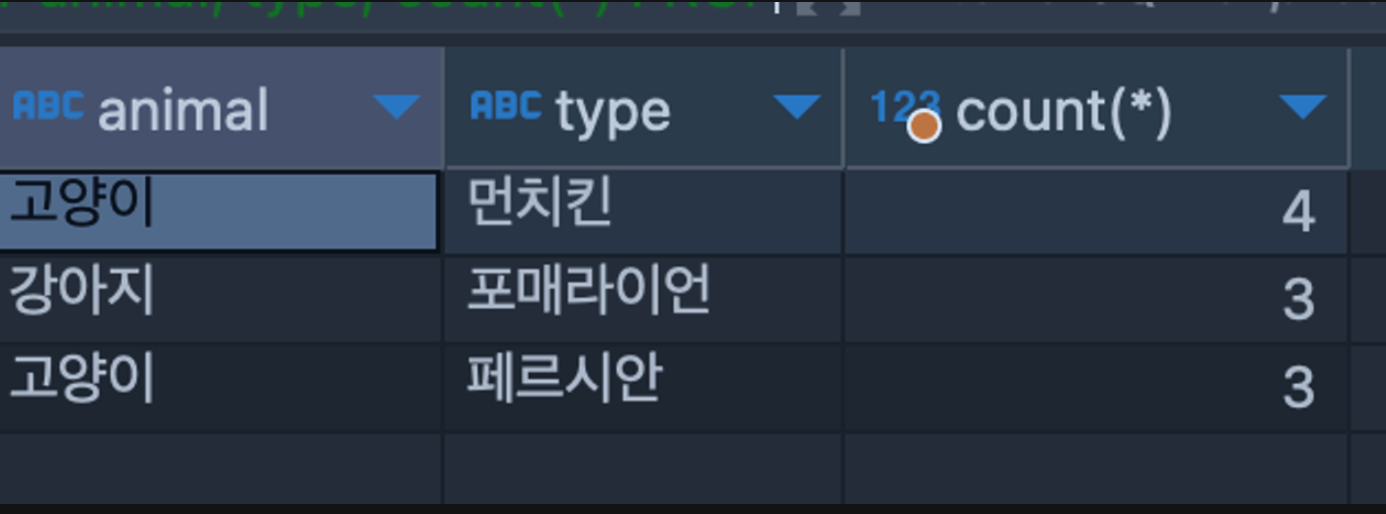
그러면 ‘고양이’의 경우만 보고싶을땐?
이럴 경우에 WHERE을 사용한다. 다음을 실행시키면 고양이의 경우만 조회할 수 있다.
SELECT animal, type, count(*)
FROM animal_info
WHERE animal ='고양이'
GROUP BY animal, type
HAVING COUNT(*) > 2
ORDER BY COUNT(*) DESC;
그런데 HAVING에도 조건을 시키면? 같은결과가 나오지 않을까?
맞다. 같은결과가 나온다. 하지만 이렇게 쓰면 안된다!
SELECT animal, type, count(*)
FROM animal_info
GROUP BY animal, type
HAVING COUNT(*) > 2 AND animal = '고양이'
ORDER BY COUNT(*) DESC;
왜 이렇게 안되는지 이해를 하기 위해선 SQL 쿼리의 프로세스를 이해해야 한다.
SQL 프로세스
1. 데이터 가져오기 (From, Join)
2. 조건문 행 필터링 (Where)
3. 그룹핑 (Group by)
4. 그룹핑 결과 필터링 (Having)
5. 결과 리턴 (Select)
6. 결과 정렬 (Order by & Limit / Offset)
SQL 쿼리는 이렇게 프로세스가 구성된다. 만약 방금 쿼리에서 animal =’고양이’조건을 HAVING절에다가 걸었으면 어떻게 될까? 조
조건문 행 필터링 없이 GROUP BY 로 grouping된다. 만약 animal 조건에서 강아지,토끼,이구아나 등등 여러가지 동물들이 있었다면? 불필요하게 프로세스 과부화를 시키는 과정이 될것이다. 지금이야 데이터가 몇개 안되니 상관없어 보일 수도 있지만, 대용량 데이터를 다루면서 이런 식으로 하면 안될 것이다.
'Programme > SQL' 카테고리의 다른 글
| WHERE 절과 HAVING 절의 차이점 (0) | 2025.03.01 |
|---|---|
| [SQL] 테이블 조회(2) - INNER JOIN, OUTER JOIN, CASE WHEN (1) | 2023.12.11 |
| [SQL] 테이블 생성 (DDL & DML) (0) | 2023.11.23 |
